Bei der Untersuchung von Zufallsvariablen kann es sinnvoll sein, ihre Unabhängigkeit oder die Art ihrer Beziehungen zu überprüfen. Die Analyse der Beziehungen zwischen den Variablen erfolgt in der Regel mit grafischen Werkzeugen (Punktwolken), kombiniert mit numerischen Indikatoren (Korrelationskoeffizienten).
Der bekannteste der Korrelationskoeffizienten ist der von Pearson. Es ermöglicht die Quantifizierung der Intensität der Verbindung zwischen den Variablen. Es wird konstruiert, indem die Kovarianz der Variablen X und Y auf das Produkt der Standardabweichungen von X und Y bezogen wird. Auf diese Weise werden Ergebnisse zwischen -1 und 1 erzielt.
Da der Pearson-Korrelationskoeffizient sehr empfindlich auf das Vorhandensein von Ausreißern reagiert, wird dringend empfohlen, ihn in Verbindung mit einer Grafik zu verwenden, um Fehlinterpretationen zu vermeiden.
Da der Pearson-Korrelationskoeffizient sehr empfindlich auf das Vorhandensein von Ausreißern reagiert, wird dringend empfohlen, ihn in Verbindung mit einer Grafik zu verwenden, um Fehlinterpretationen zu vermeiden.
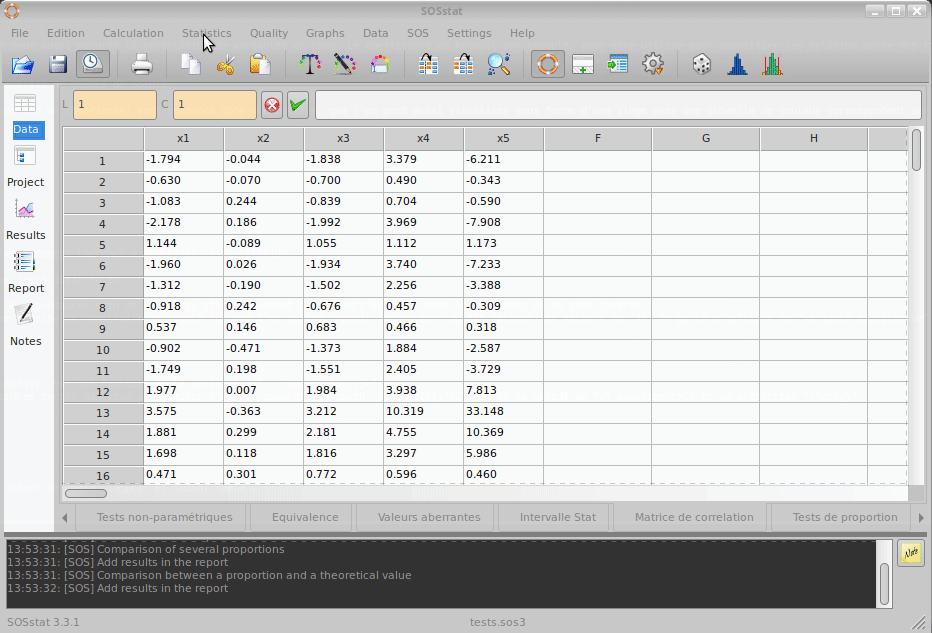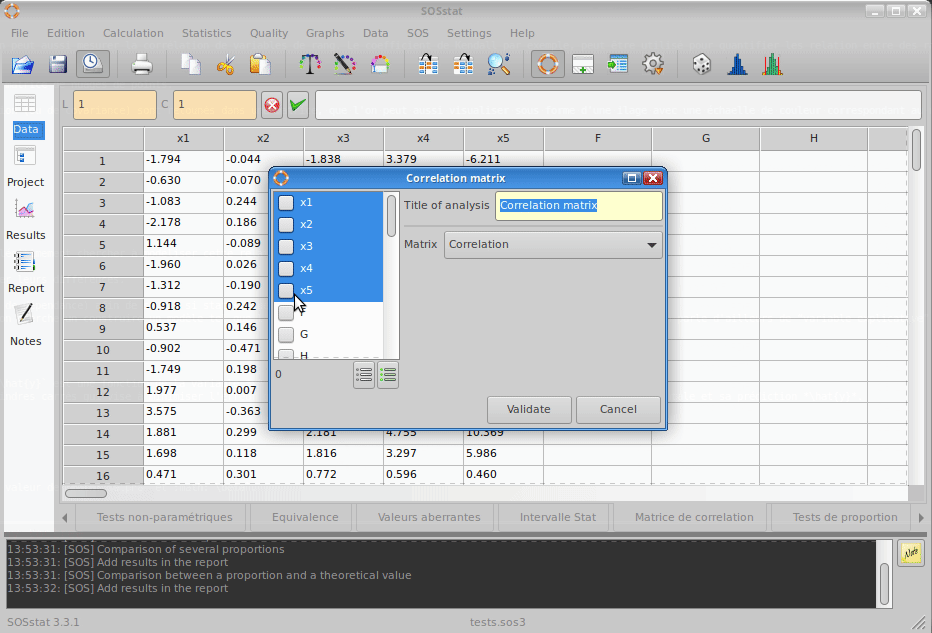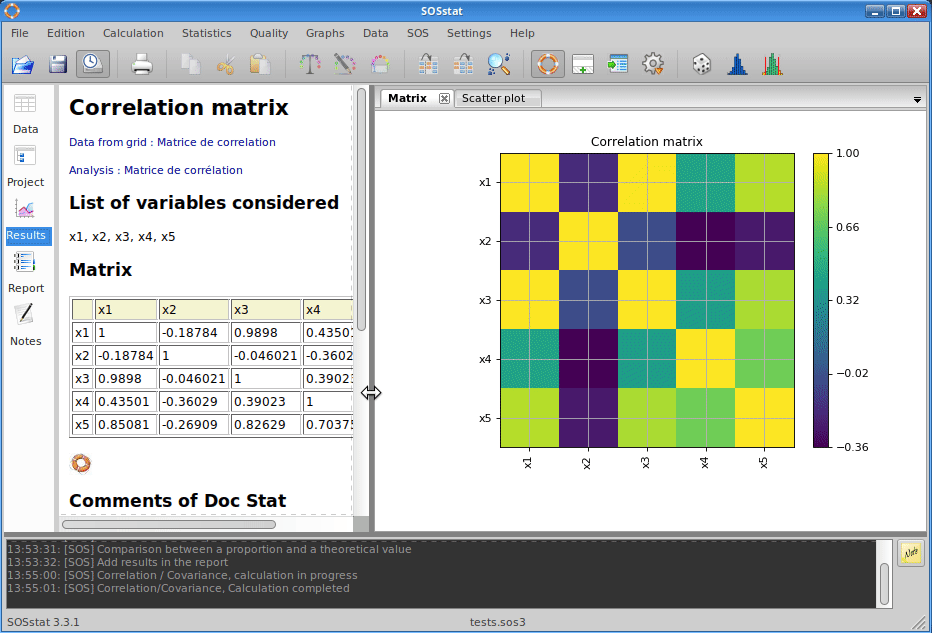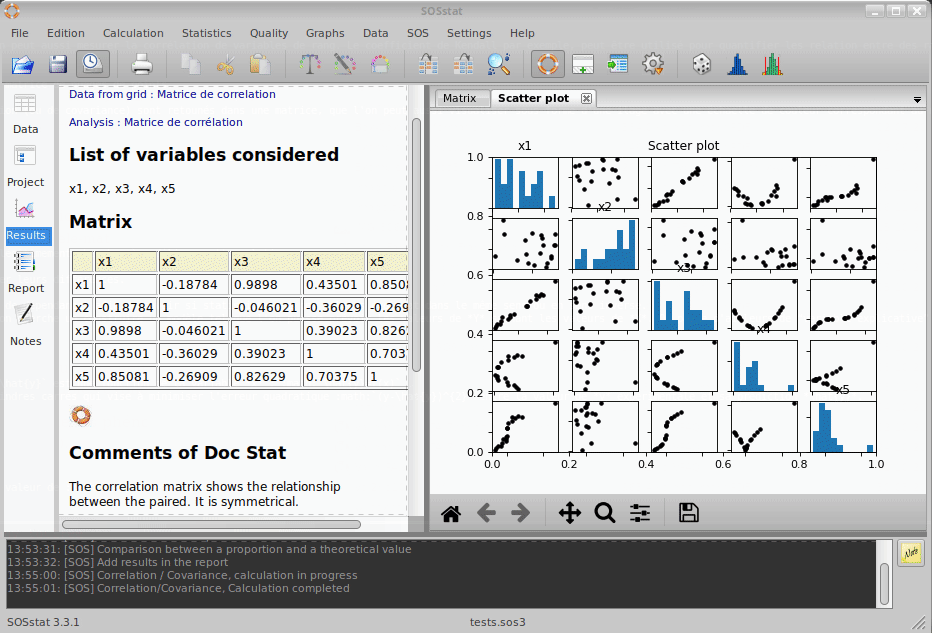
Wenn Sie die Korrelation mehrerer Variablen untersuchen wollen, verwenden Sie in der Regel eine Matrix von Punktwolken.
SOSstat ermöglicht es Ihnen, die Korrelation mehrerer Variablen zu analysieren. Die Ergebnisse der Korrelation (oder Kovarianz) werden in einer Matrix zurückgegeben, die auch als Bild mit einer dem Korrelationsgrad entsprechenden Farbskala dargestellt werden kann.
Nachdem wir die Existenz einer Korrelation zwischen zwei zufälligen Variablen nachgewiesen haben, können wir berechtigterweise versuchen, diese Beziehung zu modellieren. Der Zweck der Regression ist es, dieses Modell zu bestimmen. Obwohl die Begriffe Korrelation und Regression oft miteinander verbunden sind, lohnt es sich, an ihre Unterschiede zu erinnern.
Die Korrelation zielt darauf ab, die Intensität der Beziehung zwischen zwei Variablen (ihren Grad der Abhängigkeit) zu quantifizieren, um zu bestimmen, ob sich diese Werte statistisch in die gleiche Richtung oder in die entgegengesetzte Richtung bewegen. Der Ansatz der Regression ist etwas anders. Aus den Wertepaaren (x,y) versuchen wir, ein Modell so zu konstruieren, dass wir die Werte von Y vorhersagen können, indem wir die Werte von X kennen. Wir sprechen von „erklärender Variable“ für X und „erklärender Variable“ für Y.
Lassen Sie x und x zwei abhängige Zufallsvariablen sein. Die Vorhersage von y notiert \(\hat{y}\) ist eine Funktion der Variablen x* : \(\hat{y}=f(x)\) . Um die Koeffizienten des Modells bestimmen zu können, verwenden wir das Kriterium der Optimierung der kleinsten Quadrate, das darauf abzielt, den quadratischen Fehler \((y-\hat{y})^{2}\) zwischen dem Wert von y experimental und seiner Vorhersage hat{y} zu minimieren.
Wenn wir das lineare Vorhersagemodell in die Form bringen :
Dann ermöglicht die Anwendung der kleinsten Quadrate, die Werte von \(\alpha\) und \(\beta\) festzulegen (siehe Demonstration unten).
Leider garantiert eine gute Anwendung der Methode der kleinsten Quadrate nicht, dass das Modell von guter Qualität ist. Tatsächlich wird die Qualität der Vorhersagen davon abhängen:
Um zu überprüfen, ob das Modell einen zufriedenstellenden „erklärenden“ Charakter hat, wird die Zerlegung von Varianzen untersucht. In der Regression wird angenommen, dass die insgesamt beobachtete Variabilität (SCT) die Summe der durch das Modell (SCM) erklärten Variabilität und der Restvariabilität (SCE) ist, die Abweichungen, die das Modell nicht vorhersagen kann. Diese Beziehung wird als die Summe der quadratischen Abweichungen ausgedrückt.
wo
Diese Zerlegung der Variationsquellen ermöglicht es, den Bestimmtheitsmaßstab zu bestimmen \(R^{2}\). Der Bestimmtheitsfaktor stellt die Beziehung zwischen der durch das Modell erklärten Variabilität und der Gesamtvariabilität dar :
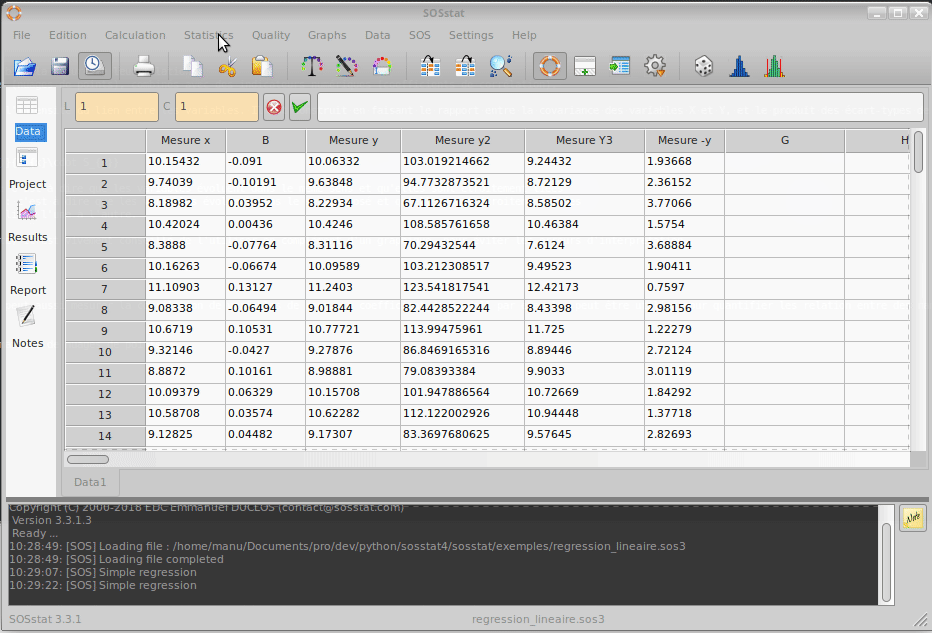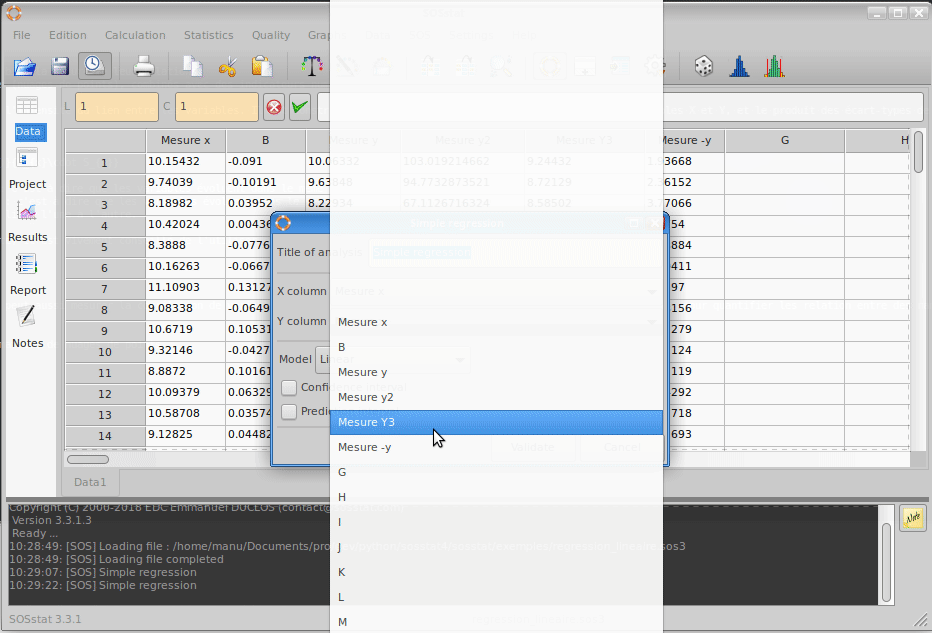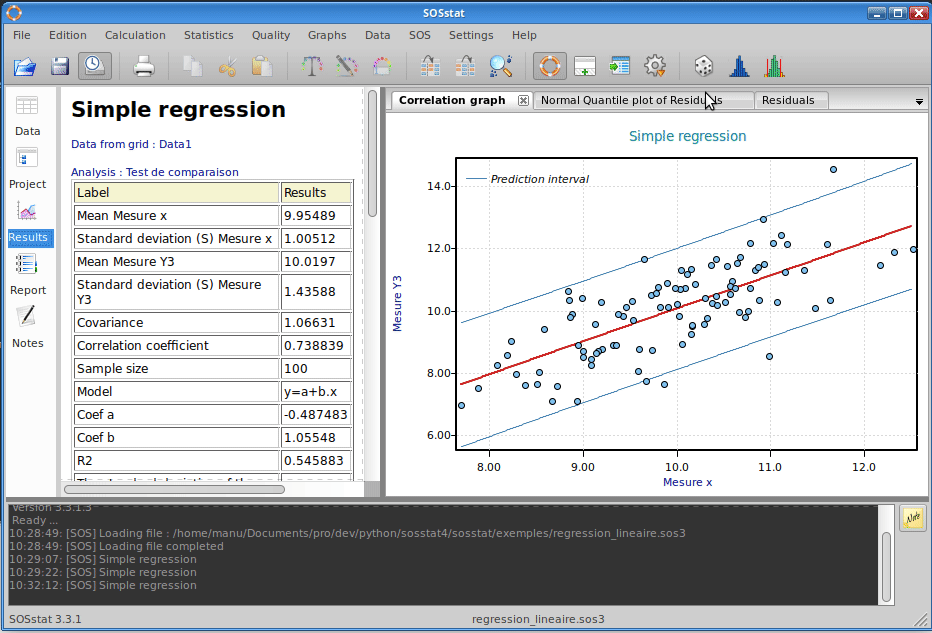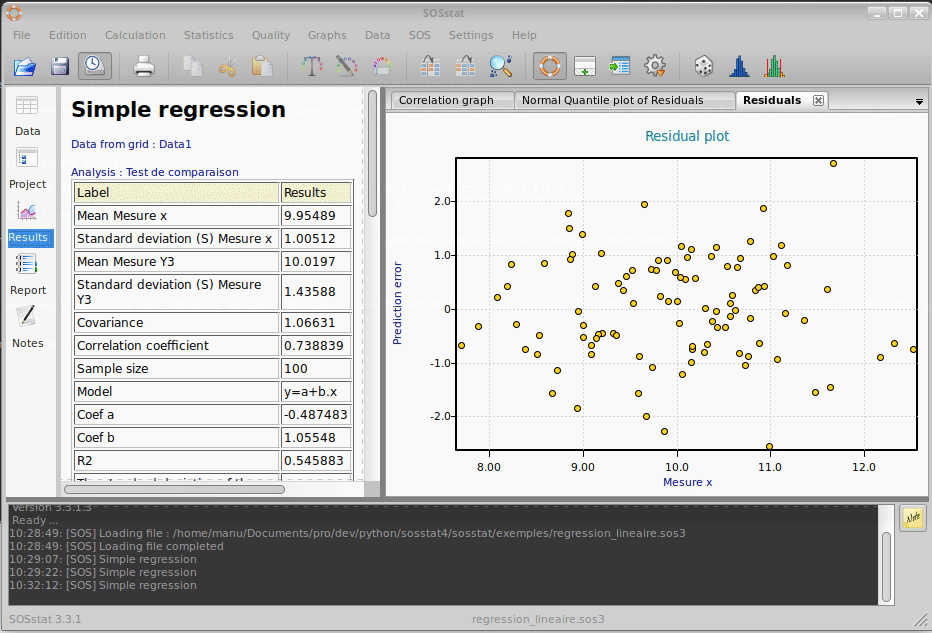
Wie in der folgenden Animation zu sehen ist, ist die Implementierung einer einfachen Regression in SOSstat extrem einfach. Der Regressionsgraph kann sowohl das Konfidenzintervall des Modells als auch das Vorhersageintervall der Beobachtungen anzeigen. Darüber hinaus wird eine Rückstandsanalyse durchgeführt, um Unabhängigkeit und Normalität zu überprüfen.
SOSstat liefert auch numerische Ergebnisse, einschließlich Modellkoeffizienten (mehrere Modelle sind verfügbar) und des Bestimmungskoeffizienten \((R^2)\). Ein Signifikanz-Test wird auf den Korrelationskoeffizienten der beiden Variablen angewendet.
Eine natürliche Erweiterung der einfachen Regression, wie vorstehend dargestellt, ist die multiple oder multilineare Regression, die es ermöglicht, ein Modell mit mehreren Eingangsvariablen zu identifizieren.
In diesem Abschnitt stellen wir den mathematischen Formalismus vor, der zur Verallgemeinerung der Methode der kleinsten Quadrate für Systeme mit mehreren Variablen verwendet wird. Matrixberechnungsmethoden werden besonders geschätzt, um Systeme von n Gleichungen bis n unbekannt zu lösen, da sie synthetisch geschrieben und einfach computerisiert sind.
Wenn wir eine Regression durchführen, ist es unser Ziel, die Parameter eines mathematischen Modells zu identifizieren. Wir können den Fall eines Systems mit zwei notierten Faktoren A und B betrachten, die wir mit einem Modell erster Ordnung darstellen wollen, d.h. mit zwei Faktoren \(E_{A}\), \(E_{B}\) und einer Interaktion \(I_AB}\). Das mathematische Modell kann dann geschrieben werden:
Das kann immer noch sehr allgemein geschrieben werden:
Dieses mathematische Modell kann für jede Kombination von Faktorstufen angewendet werden (4 Experimente, wenn beide Faktoren jeweils zwei Stufen haben). So können wir die Antworten nach \(x_{1}\) und \(x_{2}\) ausdrücken, die die Werte -1 oder +1 (reduzierte zentrierte Koordinaten) annehmen, je nachdem, ob sie sich auf der minimalen oder maximalen Ebene befinden.
Dieses System von vier Gleichungen kann in Matrixform dargestellt werden, indem man die folgenden Notationen übernimmt:
Y ist der Vektor der Antworten des Systems.
a ist der Vektor der Koeffizienten des Modells, d.h. der Effekte und Wechselwirkungen (die sehr genau organisiert sind).
X ist die Experimentiermatrix, die die Abfolge der durchgeführten Experimente oder die Beobachtung von erklärenden Variablen beschreibt.
In dieser Darstellung sind y und X bekannt und wir versuchen, die Koeffizienten von a zu identifizieren.
Das mathematische Modell, das wir zu identifizieren versucht haben, ist rein theoretisch, da es eine deterministische Beziehung zwischen der erklärten Variable Y und den erklärenden Variablen X darstellt. Um zufällige Phänomene zu berücksichtigen, wird dem Modell ein Begriff hinzugefügt, der Rückstände darstellt (Rückstände sind die nicht im Modell enthaltenen Abweichungen).
Zur Lösung dieses Gleichungssystems wird die multiple oder multilineare Regressionstechnik eingesetzt. Letzteres sucht eine Lösung, die die Summe der Quadrate der Unterschiede zwischen dem Modell und den experimentellen Ergebnissen (kleinste Quadrate) minimiert.
Die Lösung eines linearen Systems mit dem Kriterium der kleinsten Quadrate ist durch die Beziehung gegeben:
SOSstat bietet ein Modul für multiple Regression, um komplexe Modelle zu erstellen, die kontinuierliche und diskrete Variablen mischen. SOSstat berechnet die Modellkoeffizienten und führt Tests durch, um festzustellen, ob die Modellkoeffizienten signifikant sind. Zahlreiche Rückstandsanalysediagramme ergänzen die Berechnungen, um isolierte Werte zu identifizieren oder einen Anpassungsfehler (d. h. ein ungeeignetes Modell) hervorzuheben.
SOSstat bietet auch ein Vorhersagemodul, das das Regressionsmodell verwendet. Das Regressionsmodell ermöglicht es dem Benutzer, die Konfiguration der Variablen leicht zu finden, um die gewünschte Reaktion zu erreichen.