
On dispose d’une information sur la loi F(X) par un échantillon \((x_{1},\ldots,x_{n})\) de la variable X. \(\mu\) est un paramètre de la loi que l’on souhaite estimer. On note \(\phi(\mu)\) une grandeur que l’on cherche à estimer. Souvent, cette grandeur n’est autre que le paramètre \(\mu\) lui-même. C’est le cas lorsque l’on cherche à estimer la moyenne d’une loi normale. On appelle estimateur ponctuel de \(\phi(\mu)\) toute statistique \(T_{n}\) construite sur l’échantillon \(X_{n}\) .
Un intervalle de confiance est construit de manière à couvrir une plage spécifique de résultats possibles de l’estimation. Ainsi pour le déterminer, nous avons besoin de deux informations essentielles :
Une extension intéressante de la notion d’intervalle de confiance est la prise de décision statistique par des tests. Pour réaliser un test, nous allons construire un intervalle de confiance, non pas autour d’une estimation, mais autour d’une valeur qui constitue une hypothèse statistique. Cette procédure est connue sous le nom de test d’hypothèse ou test par intervalle de confiance.
Les procédures de tests d’hypothèses ou tests par intervalle de confiance sont très utilisés dans les applications Qualité. Ils sont, en effet, à la base de la construction des cartes de contrôle et du contrôle par échantillonnage.
On peut déterminer la valeur d’hypothèse de trois façons : connaissance acquise sur des observations antérieures, théorie ou modèle mathématique.
Par la suite on compare les données recueillies lors d’une expérience à la valeur d’hypothèse. En fonction du degré de confiance que l’on attribue au test et en fonction de la loi de distribution de la statistique étudiée, on peut établir une règle de décision qui doit permettre d’accepter ou de rejeter l’hypothèse émise.
Il est habituel de formuler le problème de la manière suivante :
L’hypothèse à vérifier est appelée hypothèse nulle que l’on note \(H_{0}\). L’alternative à cette hypothèse, c’est-à-dire lorsque \(H_{0}\) est fausse, est notée \(H_{1}\). La mise en oeuvre de tests d’hypothèse engendre forcément une prise de risque.
Les tests sont dit bilatéraux lorsqu’ils mettent en jeu deux limites pour définir le domaine d’acceptation de l’hypothèse \(H_{0}\). Ce cas est le plus courant, on le retrouve généralement lorsque l’hypothèse \(H_{0}\) est formulée par une égalité, et l’objectif du test est de démontrer que cette égalité est fausse.
On peut également construire des tests unilatéraux où l’hypothèse est formulée sous forme d’une inégalité.
SOSstat permet une interprétation simple des tests en représentant graphiquement la variable de test ainsi que les limites d’acceptation de l’hypothèse \(H_{0}\). Par ailleurs les commentaires de doc stat rappellent le mécanisme du test et énoncent clairement la décision à prendre.
Les applications des tests sont multiples :
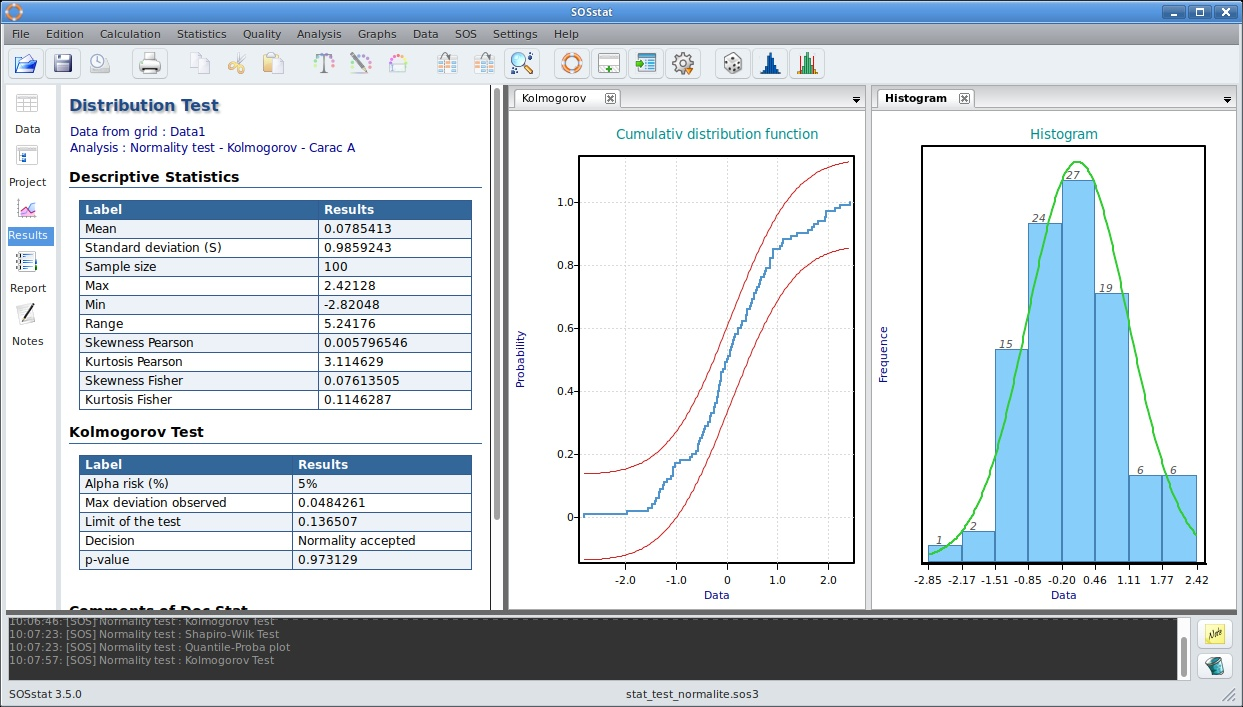
Tests de normalité de Kolmogorov-Smirnov réalisé avec SOSstat
Dans cet exemple, nous allons comparer la moyenne d’un échantillon à une valeur théorique \(\mu=250\). Pour réaliser ce test on suppose également que l’écart-type est connu : \(\sigma=0,1833\).
Un échantillon d’effectif n=10 permet de calculer la moyenne \(\overline{X}=249.3\).
On souhaite déterminer s’il existe un écart significatif entre \(\overline{X}\) et \(\mu\) pour un niveau de confiance \(1-\alpha\), on peut donc décrire les deux alternatives du test :
Nous savons que la moyenne \(\overline{X}\) suit une loi normale \(\mathcal{N}(\overline{X},\frac{\sigma}{\sqrt{n}})\)
L’hypothèse \(H_{0}\) est donc valide si la moyenne de l’échantillon se trouve dans l’intervalle de confiance :
En prenant un risque \(\alpha=5\%\) on peut déterminer le quantile de la loi normale \(u_{0.975}=1.96\). D’où l’encadrement :
La moyenne ne se trouvant pas dans l’intervalle de confiance, on rejette l’hypothèse \(H_{0}\) : l’écart est donc jugé significatif.
En pratique on préfère construire une variable de test, qui, dans notre cas, suit une loi Normale centrée réduite N(0,1) :
Pour accepter \(H_{0}\), il faut que la variable de test soit comprise entre les quantiles \(u_{\alpha}=-1.96\) et \(u_{1-\alpha}=1.96\). On confirme donc la décision précédente : l’écart entre \(\overline{X}\) et \(\mu\) est significatif.
SOSstat représente graphiquement la situation correspondant à l’hypothèse \(H_{0}\) (courbe bleue encadrée par l’intervalle de confiance). La variable de test est représentée par la courbe rouge qui se trouve à l’extérieure de l’intervalle de confiance. On rejette donc l’hypothèse \(H_{0}\)
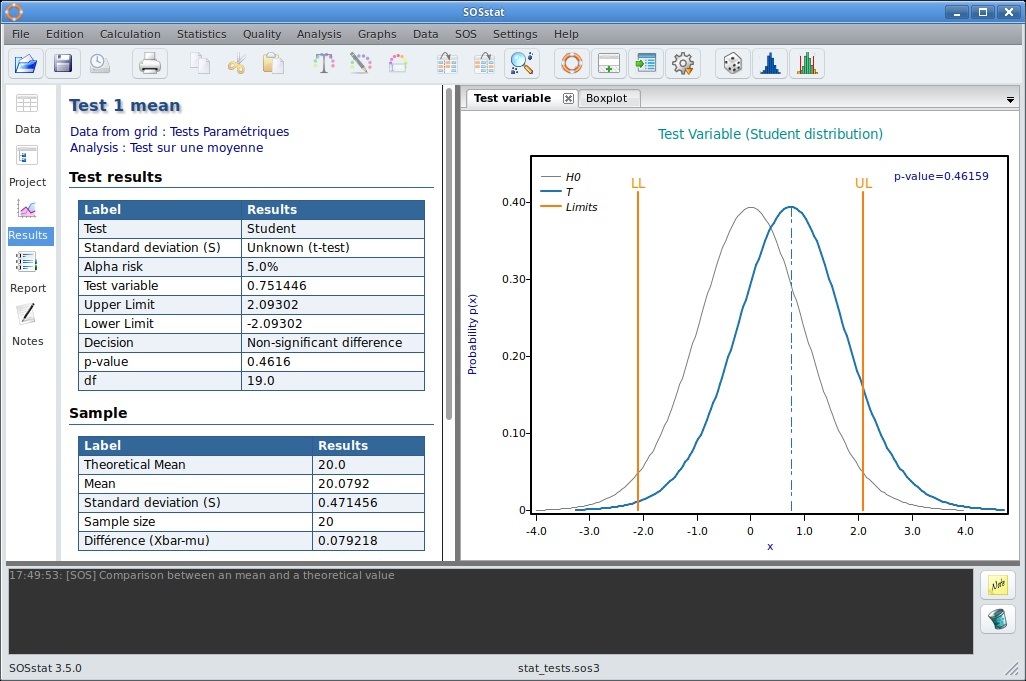
Tests sur 1 échantillon réalisé avec SOSstat
On distingue généralement deux familles de tests : les tests paramétriques et non-paramétriques. Tandis que les tests paramétriques postulent la normalité de la population et s’appuient sur l’estimation de paramètres pour prendre la décision, les tests non-paramétriques ne postulent aucune loi pour représenter le comportement des données à traiter. De ce fait, la validité du résultat est indépendante de la loi postulée, on dit que le test est “ distribution-free ”. Ces tests sont particulièrement utilisés lorsque l’hypothèse de normalité des variables utilisées n’est pas satisfaite, ou bien lorsque l’on traite des variables ordinales (classement) ou des variables discrètes.
La question qui est souvent posée, est de savoir quels sont les avantages ou inconvénients des tests non-paramétriques vis-a-vis de leurs homologues paramétriques ? Nous proposons quelques éléments de réponse.
Avantages :
Inconvénients :
SOSstat permet de réaliser de nombreux tests paramétriques et non-paramétriques :
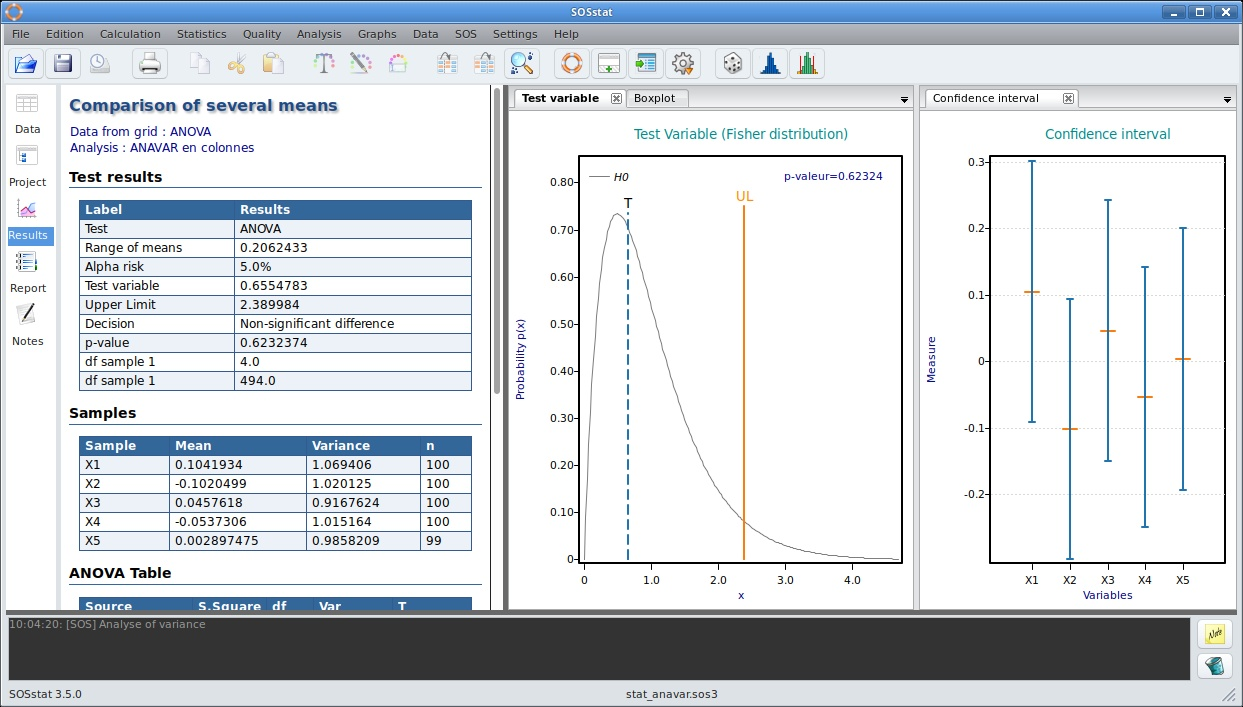
Analyse de la variance réalisée avec SOSstat
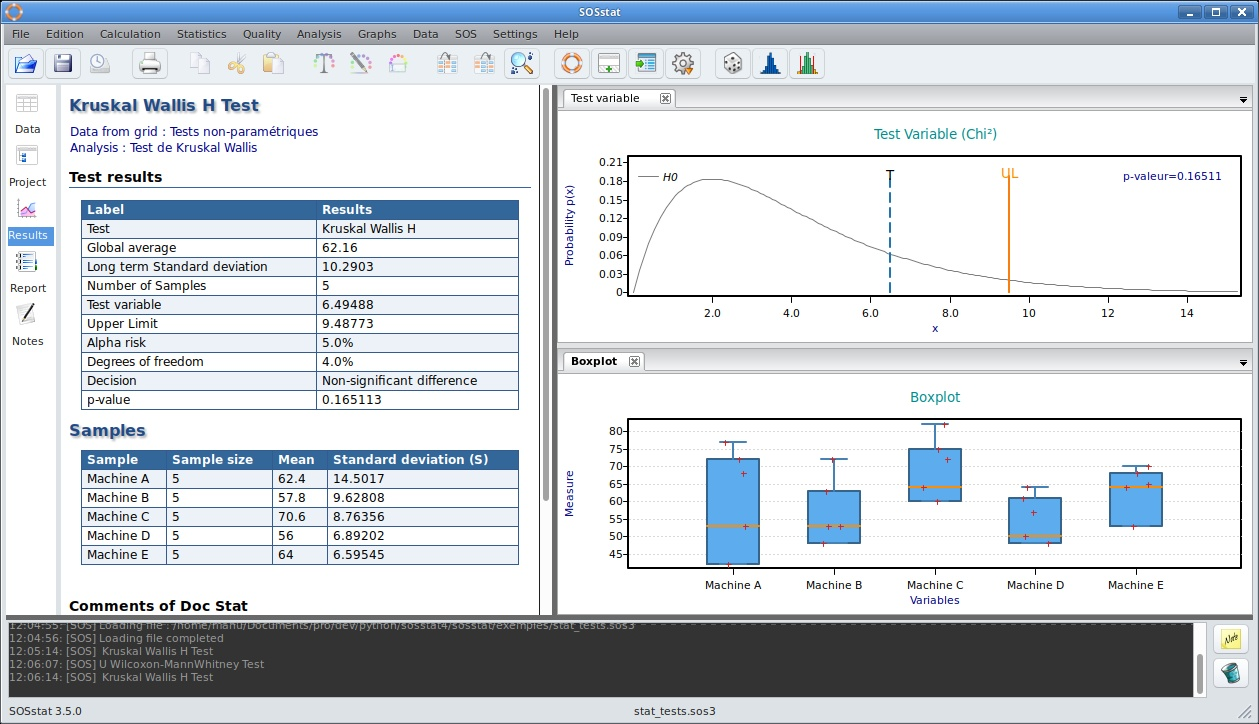
Test de Kruskal Wallis réalisé avec SOSstat

